


SberDevices анонсировала семейство моделей с открытым исходным кодом GigaAM.
Они предназначены для корректного распознавания русского языка и эмоций. Их можно использовать для написания научных статей и дипломных работ.
Семейство состоит из трех нейромоделей: GigaAM, GigaAM-CTC и GigaAM-Emo.
GigaAM — Audio Foundation Model, предобученная на русской речи. Она нужна для адаптации под различные задачи работы со звуком, включая распознавание речи и эмоций, определение диктора и многие другие.
GigaAM-CTC является моделью для распознавания русскоязычных запросов. По данным компании, модель допускает в коротких запросах на 20–35% меньше ошибок в словах в сравнении с NeMo-Conformer-RNNT и Whisper-Large-v3.
GigaAM-Emo — это акустическая модель для определения эмоций. Она стала лучшей на крупнейшем датасете Dusha среди известных моделей.
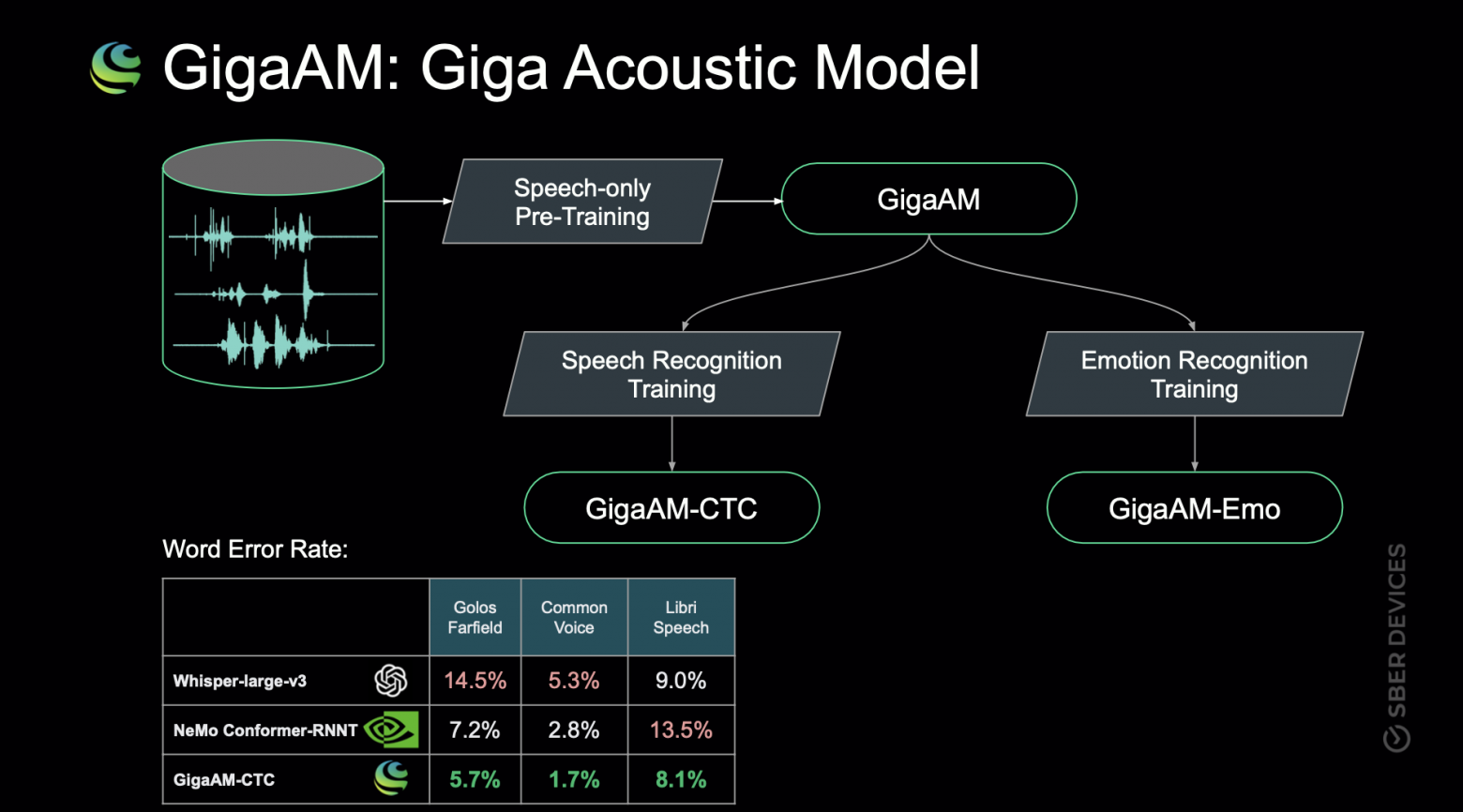
Сравнение GigaAM с аналогами
SberDevices отмечает, что все новые модели размещены в открытом доступе с некоммерческой лицензией.
Новинки доступны на платформе SaluteSpeech API и в приложении SaluteSpeech App. Бизнес сможет интегрировать ботов на их базе в свои решения, а пользователи приложения, к примеру, смогут протестировать распознавание на лекциях или в ходе совещаний.

 (9 голосов, общий рейтинг: 4.89 из 5)
(9 голосов, общий рейтинг: 4.89 из 5)Артём Баусов
@DralkerГлавный по новостям, кликбейту и опечаткам. Люблю электротехнику и занимаюсь огненной магией. По всем вопросам пишите в Telegram: @TemaBausov











4 комментария
Форум →